
Ch2
Ch2
Summary
指令及指令序列
- 汇编语言表示法
- RISC 指令集
- 指令执行
- Straight-Line Sequencing and Branching
指令格式
- 指令表示方式
- 常见指令地址子段格式
- 零、一、二、三地址指令
- Opcode Format (Expanding Opcode) 操作码格式(扩展操作码)
寻址方式(Addressing Modes)
- The different ways in which the location of an operand is specified in an instruction. 在指令中决定操作数位置的不同方式。
- 典型的有 RISC 的寻址方式
堆栈处理和子程序
CISC 指令集
- 自动递增,自动递减,相关模式
- 条件编码
CISC 和 RISC 指令集的比较
指令和指令序列
四种类型的指令:
- 数据在存储器和控制器的寄存器中传递
- ALU 中对数据的算术和逻辑操作
- I/O 设备传递
- 程序序列和控制
寄存器传递表示法(Register Transfer Notation)
用于描述硬件层面数据的传递和操作。
首先介绍相关的表示法:
- 控制器寄存器:
R0,R5。 - I/O 寄存器:
DATAIN,OUTSTATUS。 - 存储器地址:
LOC, PLACE, A, VAR2。 [...]:用于表示存储在地址中的数据- $ $用于表示传递数据到指定地址。
一般来说:右边的表达式表示的是一个值,左边表示一个地址。
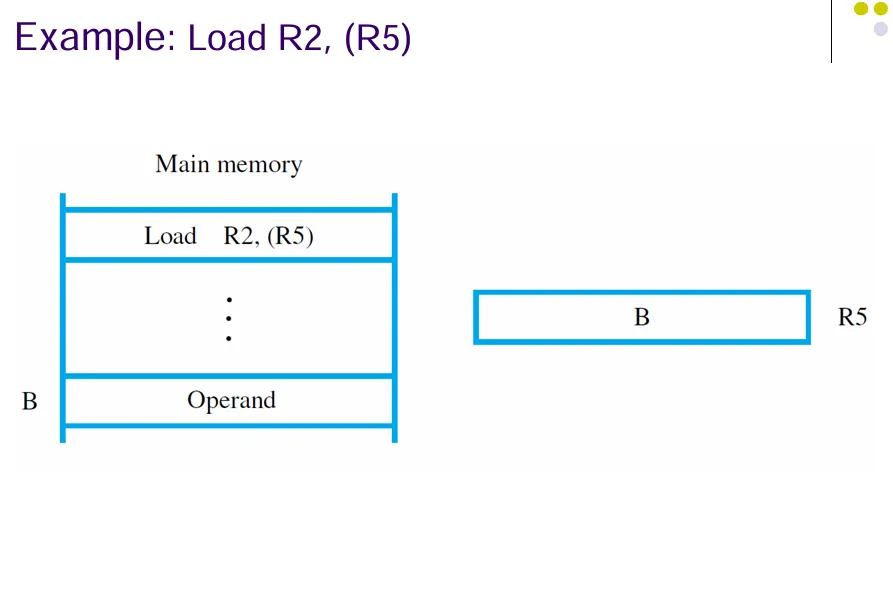
Example1: R2 <-[LOC] |
汇编语言表示法(Assembly-Language Notation)
寄存器指令表示法:表示数据传递和算术运算
而汇编语言表示法用于表示机器指令和程序,对应上面的两个例子:
Load R2, LOC |
一条汇编指令包含需要的操作数和操作。
实际上商业处理器一般使用助记符,并且不同处理器之间的助记符也是不同的。
RISC 和 CISC 指令集
指令的本质使得计算机不同。
有两种基础的方法来为现代计算机设计指令:RISC,CISC
RISC:
- 一个字的指令,需要操作数位于寄存器中
- 是一个小的指令集
- 比较简单,每个指令执行只需要一个周期的时间
- 可以高效使用管道(Effective use of pipelining)
- 典型例子 ARM
CISC:
- 多个字的指令,且运行操作数直接从存储器中获取
- 指令数目非常庞大
- 一个执行需要多个周期进行执行
- 典型例子 X86
RISC的关键特征:
- 每条指令占据一个字
- 使用
load/store结构:意味着只有load或store指令可以访问存储器中的操作数,并且用于算术运算或者逻辑运算的操作数必须来自于寄存器,或者是在指令字直接显式地给出。
Load指令一般格式如下:
Load procr_register, memloaction |
最初指令和数据位于存储器中,根据 RISC 指令集架构的特点,数据被传输到寄存器中(这里涉及到寻址方式,后续介绍)。
简单例子如下:
//高级语言 |
//寄存器表示法 |
//Load指令将数据传输到寄存器中 |
Instruction Execution and Straight-Line Sequencing
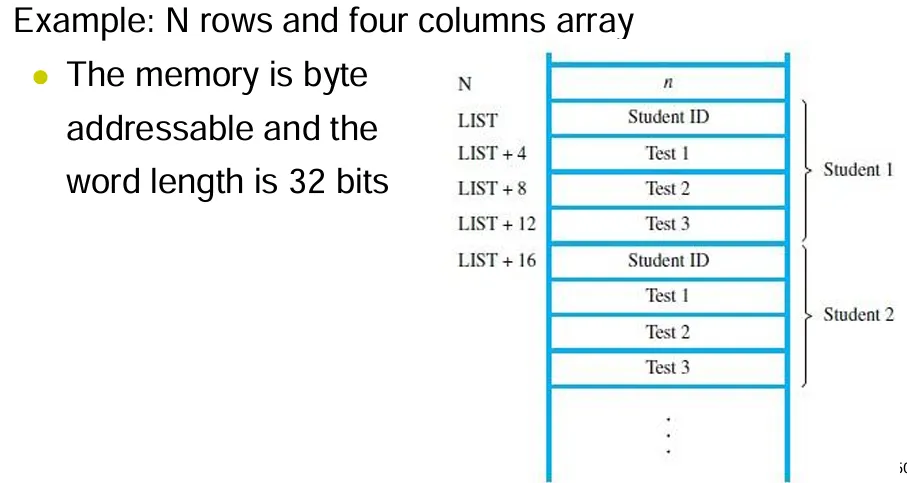
假设一个字长是 32 位,存储器是可按字节寻址的,可以在 Load 和 Store 指令中直接指定需要的内存位置。
简单来说:顺序执行指令如下:
[PC] = i |
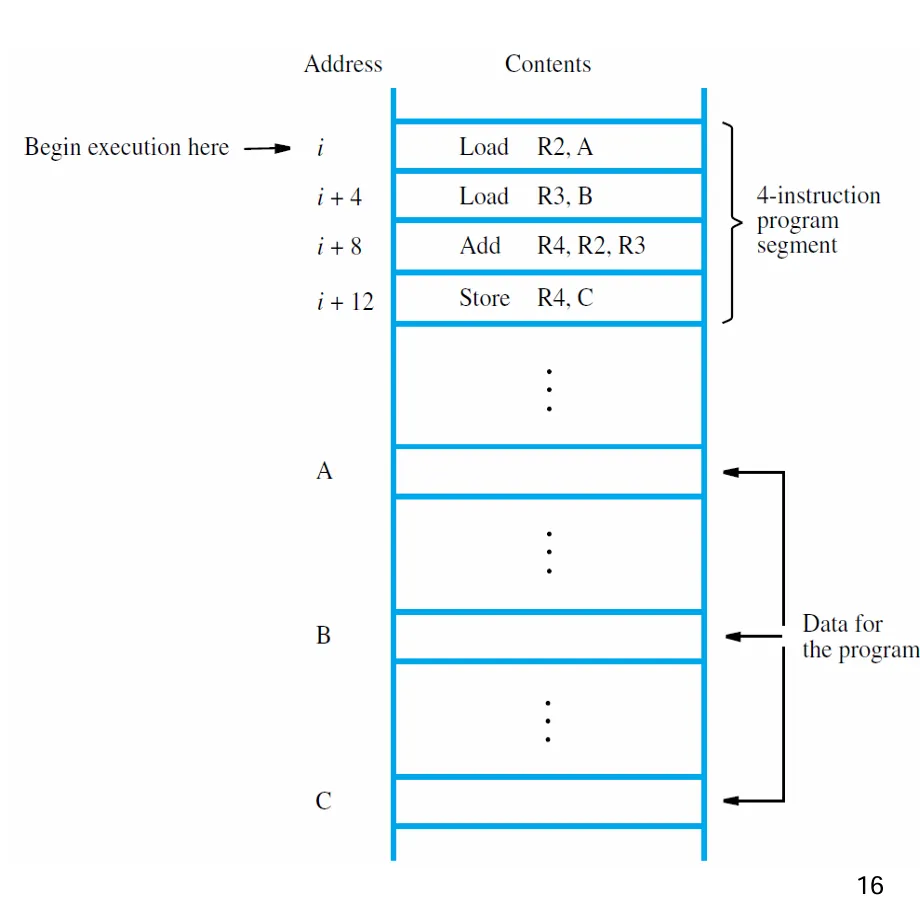
在上一章我们知道:指令是需要两个阶段执行的:获取指令,执行指令。
分支执行
假设现在有一个任务,我们需要将\(n\)个数进行相加,并且将结果进行存储。
可以发现我们需要执行多次 Add,Load 指令,并且涉及多个操作数,一种可能的方法如下:
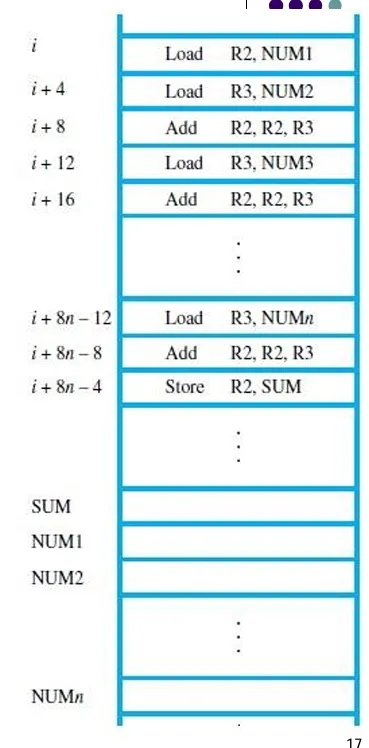
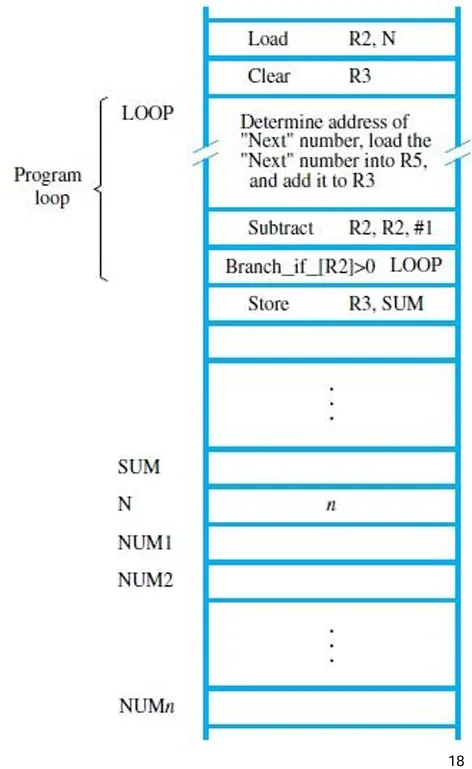
不难看出这样需要消费大量的内存空间,我们采用另外一种方法:分支(Branching)
- 使用循环
- 分支指令:我们需要加载一个新地址到 PC 中,并且确定分支目标。
- 条件分支:
- 对两个寄存器中的内容进行比较,判断是真是假,从而选择是否继续执行循环,关键在于条件的编码。
指令格式
机器指令:为了执行需要的任务,将所要的行动转换为可被处理器回路执行的一系列指令。通常使用汇编表示。
指令集:处理器可以执行的一系列机器指令的集合。
机器指令要素
- 操作码:描述要进行的操作:如 Add 或 I/O 等,一般表示为二进制编码。
- 源操作数引用:指定指令需要的操作数。
- 结果引用:
- 结果操作数或者源操作数可以被存放到三个位置中:主存或虚存,处理器寄存器,I/O 设备
- 下一条指令引用:指令在程序中是线性的,逻辑上可以认为:下一条指令跟在当前指令的后面。
指令表示法及设计标准
在计算机中,指令是由一段二进制序列进行表示的,分为两段:操作码+地址。
设计标准:
- 短指令比长指令更好
- 确认地址子段的比特位数
- 足够的空间表示所有的操作
指令地址子段
分为 0,1,2,3 三种:


指令长度
分为两种:固定字长和可变字长。
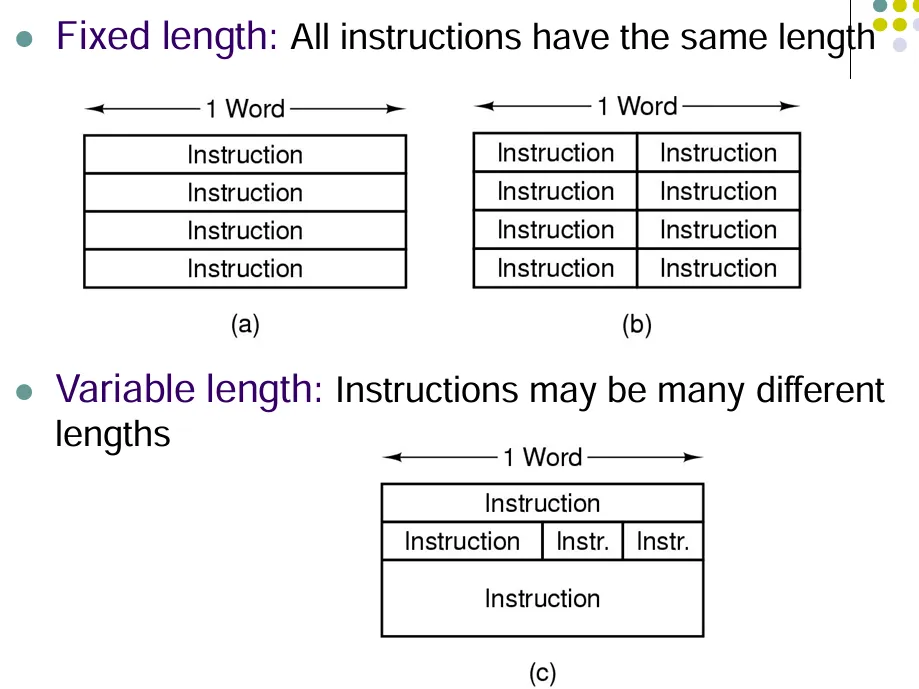
如果一个操作数被多次使用,可以将其存储在寄存器中,也可以隐式指定一个或者多个操作数。
操作数编码
分为固定字长和可变字长:
固定长度:
- 操作码的字长是固定的,但指令的长度是可变的。
- 假设有\(k\)位的操作码,\(n\)位的操作地址:
- 可以执行\(2^k\)种操作
- 可以有\(2^n\)个可访问存储单元
可变长度(扩展操作码):
指令的长度是固定的,操作码和地址的长度相互限制:
- 16 位的指令,假设现在处理器有 16 个寄存器,我们可以分配 4 位用于一个地址(恰好能够支持所有寄存器的访问),另外根据前面提到的三种地址字段,如果是三个操作数情况:则 4 位分配给操作码,剩下 12 位分配给 3 个地址。所以可以有 16 条操作码。
练习题:设计指令集(假设是 16 个寄存器,指令长度为 16 位,操作数地址为四位)
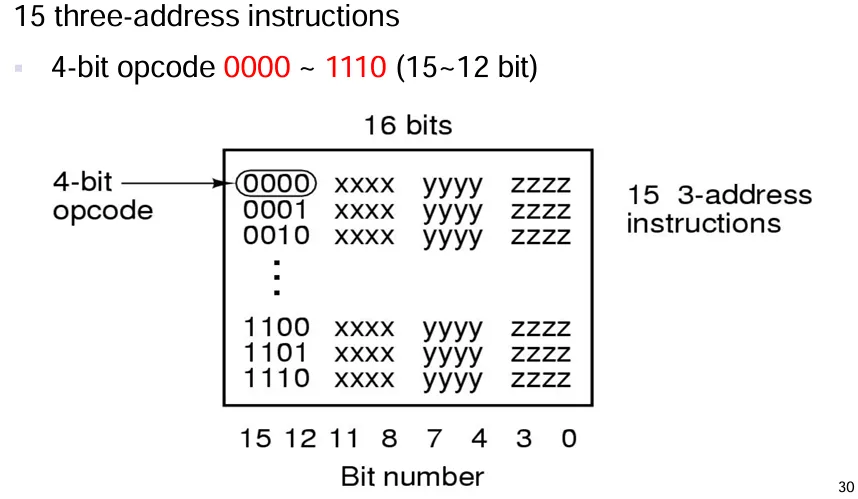
15 条 3 地址指令:
15-12位共四位表示操作码,11-0位,每四位表示一个操作数地址。对应的 15 条指令为:
0000-1110,因为只有 15 条,所以不需要1111。
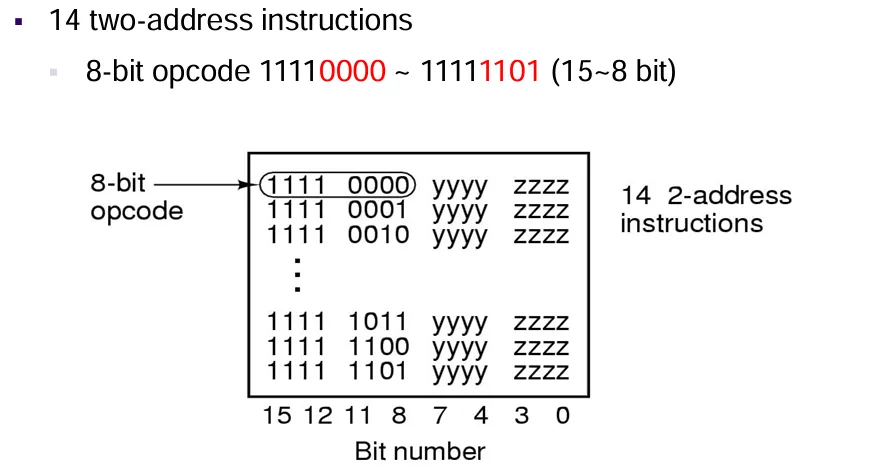
14 条 2 地址指令:
8 位表示操作码,剩下的 8 位表示两个操作数地址。
可以将最高 4 位全部置为 1,然后
11-8位表示实际的操作码(一共是15-8位)从
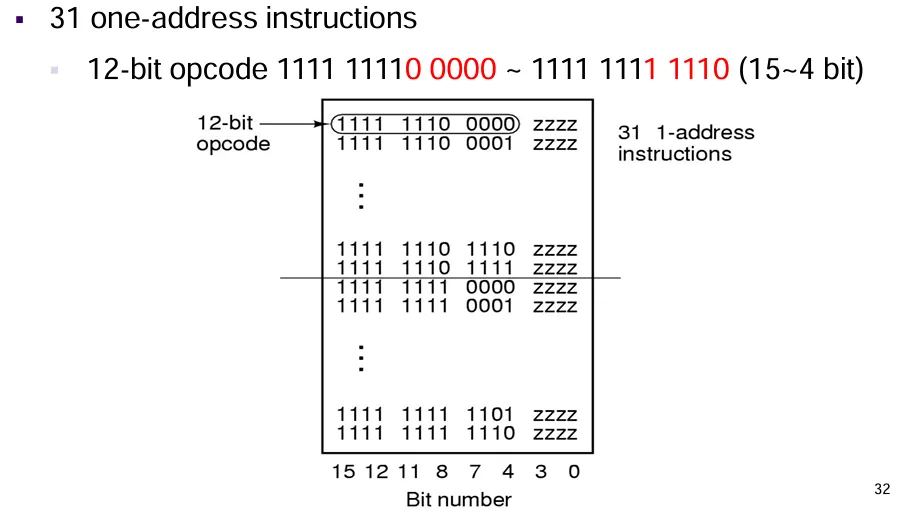
11110000 - 11111101。31 条 1 地址指令:
4 位表示操作数地址,5 位表示指令,剩余全部置为 1。
从
1111 1110 0000 - 1111 1111 1110。这里
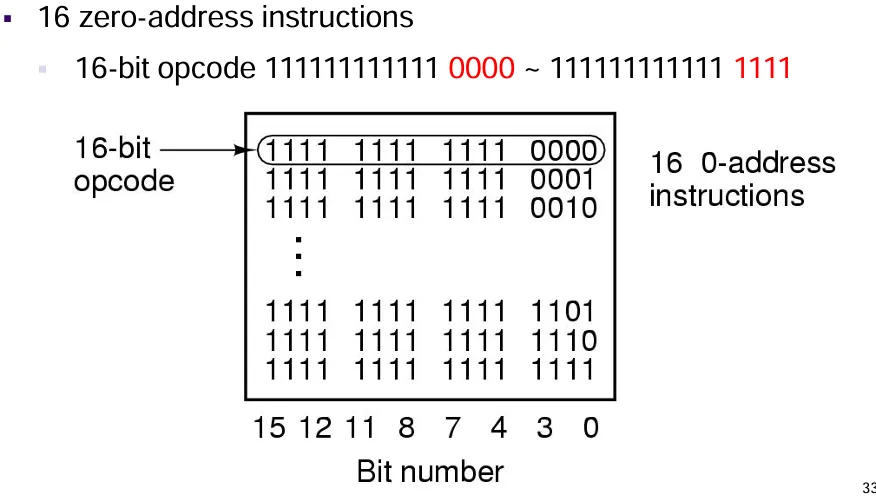
PPT有错误,注意一下:16 条 0 地址指令
4 位表示操作码,剩余位全部置为 1。
从1111 1111 1111 0000 - 1111 1111 1111 1111。
寻址方式
寻址方式:用于寻找指令中指定操作数的方法。
有 6 种:立即方式,寄存器方式,绝对方式,寄存器间接寻址,变址方式,带变址的基址方式。
建议英文,比较好想:Immediate, register, absolute, register indirect, index, base with
Immediate
操作数直接给定,用于定义和使用常量,对某些变量设定初始值。
优点是不需要存储器访问,缺点是只能作为常量进行使用,并且大小被限制在地址子段的大小内(本质上是一个操作数,占用和地址子段一样多的位数,所以能够表示的范围也是有限的)。
常见的有:
//格式
[OP][][Operand]
Add R4, R6, #200
Absolute
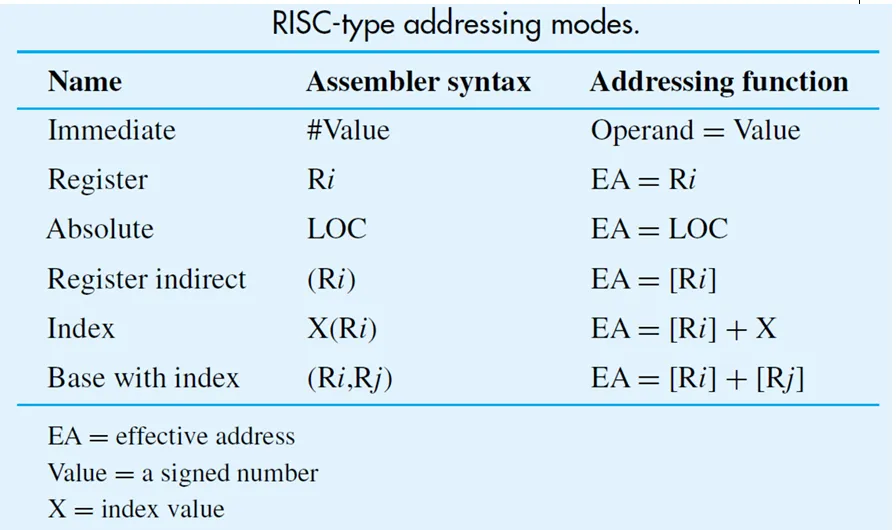
操作数在存储器单元中,地址被显式地给定在指令中。在编译时期,可以访问地址已知的全局变量。
优点是只需要对存储器的引用且不需要额外的计算。
缺点是需要经常访问同一个存储器地址,并且只能提供有限范围内的地址空间。
Example: Load R2, NUM1 |

Indirect(注意不是 RISC 的)
Indirect addressing through a memory location is also possible, but it is found only in CISC-style processors.
操作数字段内容是一个存储单元中的内容,表示这个操作数的地址,简单来说就是一个指针。
优点:可以访问非常大的地址空间,如果存储器的字长是\(n\)位,那么\(2^n\)个地址空间是可以访问的。
缺点:需要对存储单元进行两次访问才能获取操作数,第一次是获取地址,第二是获取操作数。
由此可以拓展到多层间接寻址:EA=[..[A]..]。

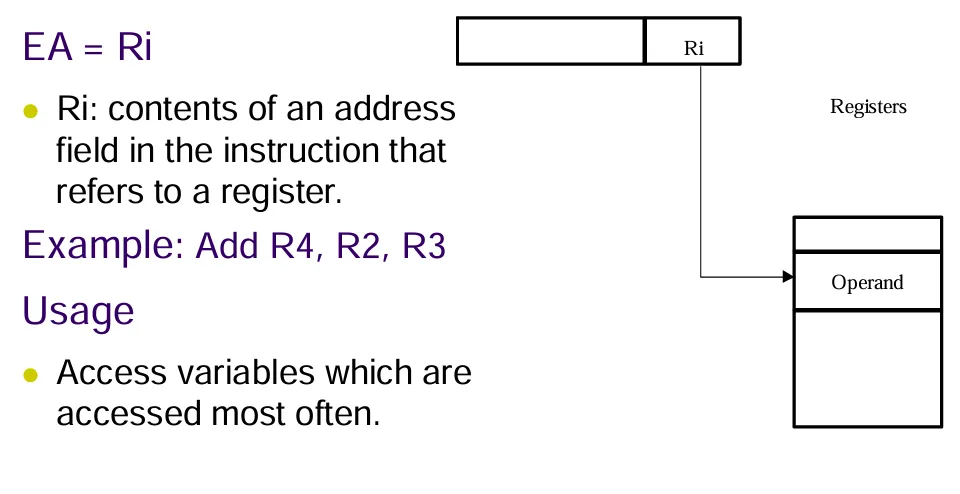
Register
操作数是处理器寄存器中的内容,寄存器的地址在指令中显式给出。一般用于操作数被经常使用。
优点是只需要一个小的地址子段,不需要对存储器单元的访问。
缺点是地址空间是有限的,也就是寄存器的数目是有限的。
格式:
EA = Ri |
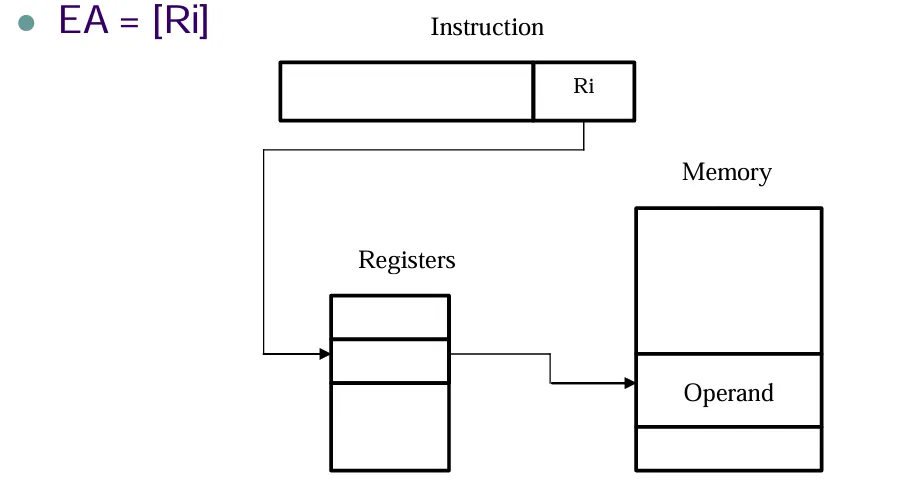
Register Indirect
可以类比前面的 Indirect,操作数的有效地址是寄存器中的内容。
优点是可以访问存储单元,但是不需要在指令中占据一个完整的存储器地址,并且减少了存储器的访问次数。

Indexed
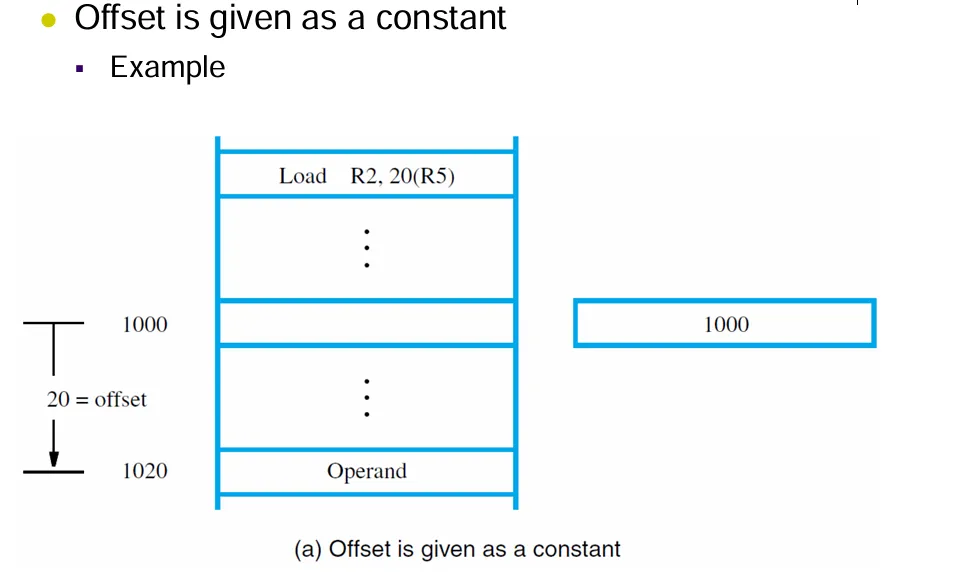
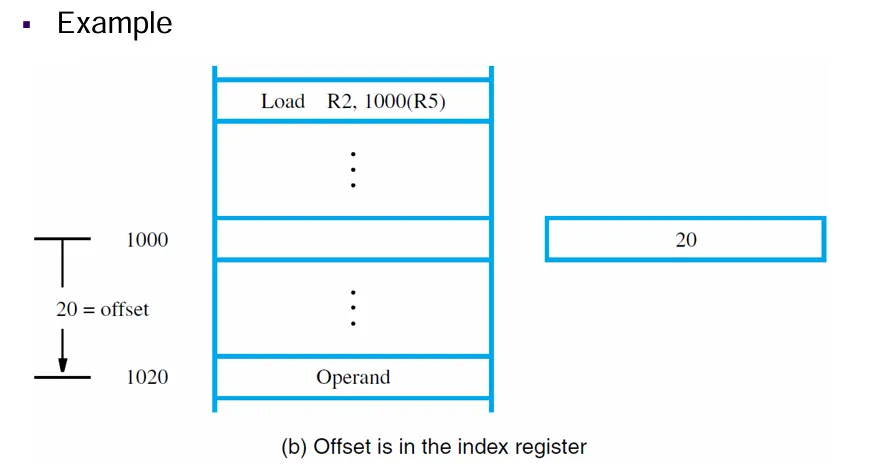
有效地址是将寄存器中的内容和X相加后得到的结果。X是一个常量。
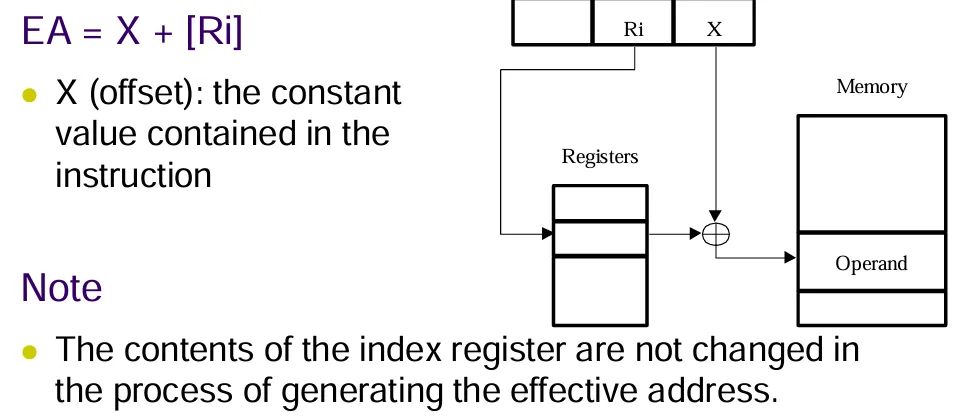
有两种使用方式:可能是偏移量在寄存器中给出,也可能是偏移量作为常量给出
Facilitate access to an operand whose location is defined relative to a reference point within the data structure in which the operand appears.方便对操作数的访问,该操作数的位置是相对于出现操作数的数据结构中的引用点定义的。
可能常见用于数组。

一些变体如下:
X可能是由另外一个寄存器中的地址指向的内容替代的。

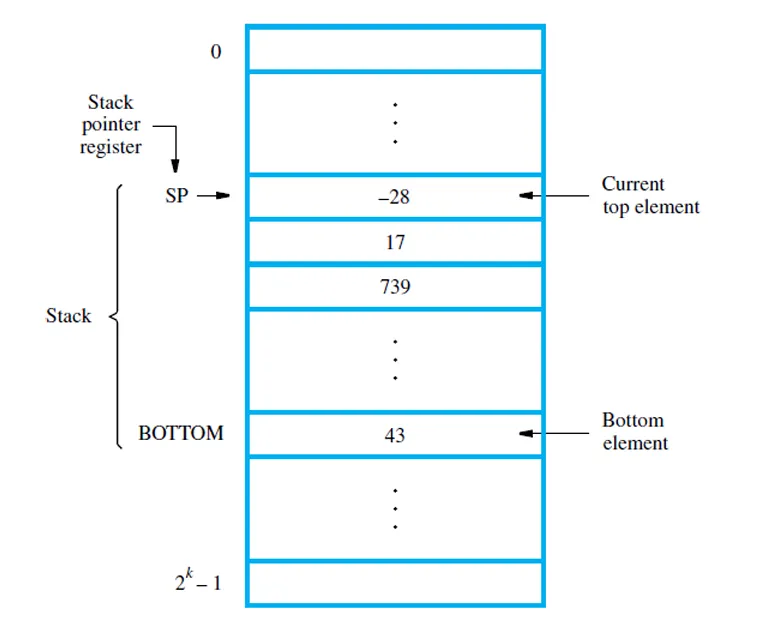
栈
一种数据结构,先进先出。在计算机中,可以由一段主存单元实现,又称为处理器栈。
拥有一个指针 SP:指向栈顶。(是一个寄存器)
假设一个字长是 32 位的计算机:方向是自底向上
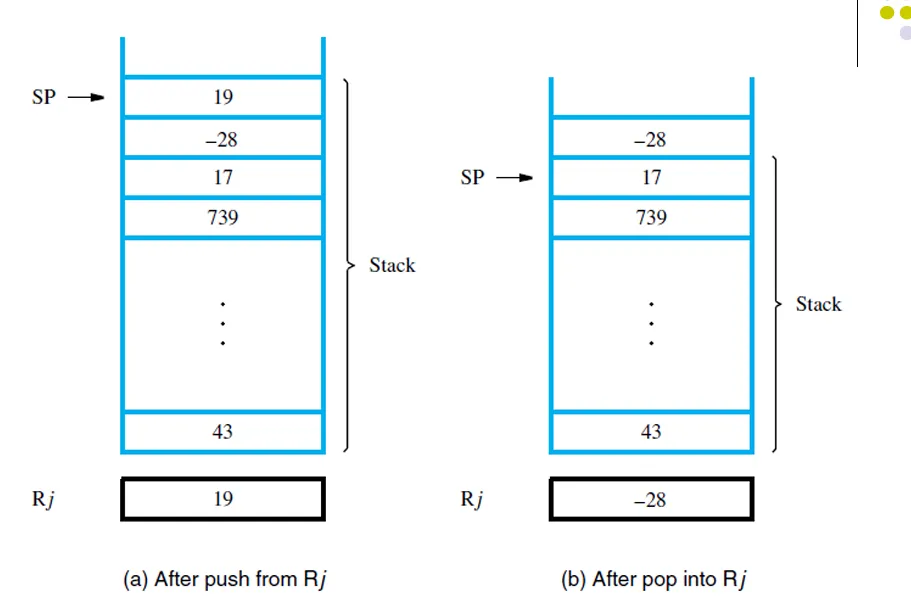
Push: |
子程序
在一个给定的程序中,一个任务可能被执行多次(数据不同)例如函数等。
将其编码为一块指令,称为子程序。
子程序调用:重复使用这一块指令,通过 Call
指令实现分支(本质上是分支跳转),可以节省存储空间,但必须能够返回分支。并且子程序在执行完毕后,必须能够返回到调用程序,以Return指令结束。
子程序链接(Subroutine Linkage)
- 在执行 Call 中,PC 更新:指向 Call 指令后面的指令。
- 保存地址空间:为 Return 指令使用。最简单的方法是将地址放在 link register 中
- Call 指令执行两个操作:存储更新后的 PC 中的内容在 link register 中,然后分支跳转到子程序的地址。
- Return 指令只执行分支跳转到存储在 link register 中的地址。
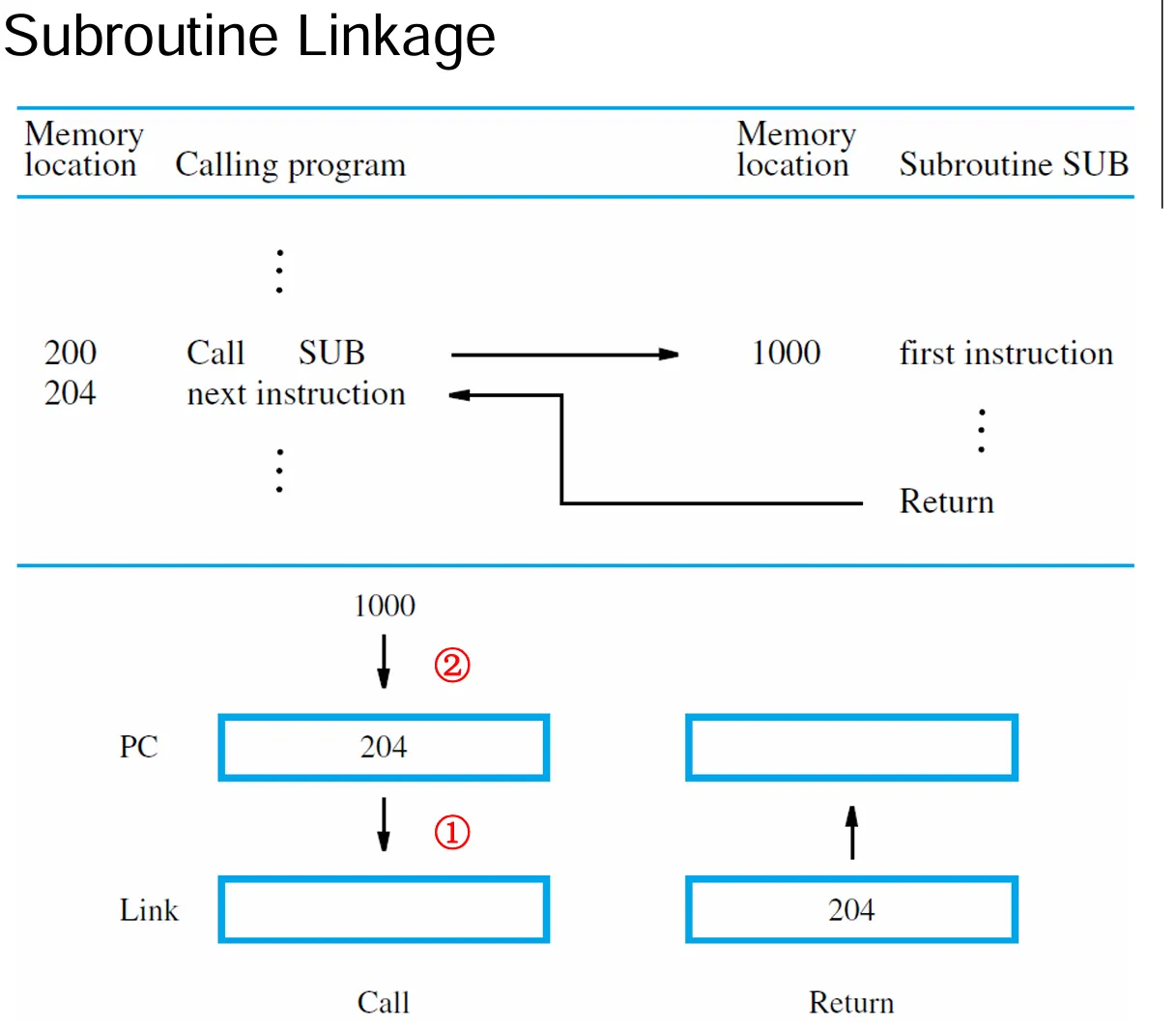
由此可以进行一系列子程序嵌套:假设现在有两个进行嵌套,那么当第一个子程序调用后,为了执行第二个子程序时,link register 需要被重写(腾出空间),实际上对应的操作是,第一个子程序在执行第二个子程序调用前,需要将 link register 保存在处理器栈中。当第二个子程序结束时,第一个子程序的 link register 中的内容将会被重新载入。
可以发现符合后进先出的特征,所以可以使用栈实现子程序返回地址的存储。
CISC 指令集
没有受限于 load/Store 体系结构,并且指令长度不一定是一个字长。大多数逻辑算术运算执行的是两个地址的形式,如:
Add B, A |
MOVE 指令执行 Load 和 Store 的功能:
Example: C = A + B |
选址方式还有自增,自减:
自增寻址:操作数的地址是存储器中的内容,并且在获取到操作数后,存储器中的内容会进行自增,指向列表中的下一个元素。

自减寻址:寄存器中的内容先进行自减,然后作为这个操作数的地址进行使用。

相对方式寻址:
就是将寄存器间接寻址法中,寄存器替换为[PC]。

条件码:处理器执行的结果存在某些信息,维护后可用于后续的状态转移。
N:如果为 1,表示负数
Z:如果为 1,表示 0
V:如果为 1,表示溢出
C:如果为 1,表示进位
一个对应的条件转移例子如下:

CISC 和 RISC 的对比:

CISC 和 RISC 比较
看书。





