SCUT2011 Data Structure
SCUT2011
Select the correct choice.
(5)
The linear list (\(a_1, a_2, \cdots, a_n\)), which is in Sequential Storage, when we delete any node, the average number of moving nodes ( ).
- \(n\) (B) \(n/2\) (C) \((n-1)/2\) (D) \((n+1)/2\)
答案:(C)
答案解释:
在顺序存储的线性表(\(a_1, a_2, \cdots, a_n\))中删除节点时,假设删除每个位置节点的概率是相等的(都为\(\frac{1}{n}\))。
如果要删除第一个节点,后面的\(n - 1\)个节点都需要依次向前移动一位,移动节点数为\(n - 1\);如果删除第二个节点,后面\(n - 2\)个节点需要向前移动,移动节点数为\(n - 2\);以此类推,删除最后一个节点(第\(n\)个节点)时,不需要移动任何节点,移动节点数为\(0\)。
那么总的移动节点数的期望(也就是平均移动节点数)为:
\[ \begin{align*} &\frac{1}{n}×[(n - 1) + (n - 2) + \cdots + 1 + 0]\\ =&\frac{1}{n}×\frac{n(n - 1)}{2}\\ =&\frac{n - 1}{2} \end{align*} \]
所以平均移动节点数为\(\frac{n - 1}{2}\),答案选(C)。
(6)
- Which of the following is a true statement: ( )
A general tree can be transferred to a binary tree with the root having both left child and right child.
In a BST, the node can be enumerated sorted by a preorder traversal to the BST.
In a BST, the left child of any node is less than the right child, but in a heap, the left child of any node could be less than or greater than the right child.
A heap must be full binary tree.
答案:(C)
答案解释:
选项 A: 一般树转换为二叉树采用孩子兄弟表示法,转换后的二叉树其根节点只有左子树(对应原树的第一个孩子)和右子树(对应原树第一个孩子的兄弟节点依次连接构成),并非随意根节点有左、右两个子树,所以该选项错误。
选项 B: 二叉搜索树(BST)通过中序遍历才能得到节点按关键字有序排列的序列,前序遍历并不能保证节点按排序后的顺序枚举出来,所以该选项错误。
选项 C: 在二叉搜索树(BST)中,确实有性质规定任何节点的左子树节点值都小于该节点值,右子树节点值都大于该节点值;而在堆中(无论是大顶堆还是小顶堆),只是要求父节点和子节点之间满足堆的大小关系(大顶堆父节点大于等于子节点,小顶堆父节点小于等于子节点),对于左子节点和右子节点之间并没有严格规定谁大谁小,左子节点可能小于也可能大于右子节点,所以该选项正确。
选项 D: 堆是一种完全二叉树结构,但说“必须是满二叉树”就不准确了,满二叉树要求每一层节点都是满的,而堆只需要是完全二叉树形态(除了最后一层节点从左到右依次排列,其他层节点数都是满的)即可,所以该选项错误。
(9)
(9)Which is wrong in the following statements ( ).
Each vertex is only visited once during the graph traversal.
There are two methods, Depth-First Search and Breadth-First Search, to traverse a graph.
Depth-First Search of a graph isn't fit to a directed graph.
Depth-first search of a graph is a recursive process.
答案:(C)
答案解释:
选项 A: 在图的遍历过程中(无论是深度优先搜索还是广度优先搜索),为了避免重复访问以及陷入死循环等情况,通常每个顶点确实只会被访问一次,会通过标记等方式来记录顶点是否已被访问过,所以该选项正确。
选项 B: 深度优先搜索(DFS)和广度优先搜索(BFS)是图遍历常用的两种基本方法,深度优先搜索沿着一条路径尽可能深地访问顶点,广度优先搜索则是按照层的顺序逐层访问顶点,所以该选项正确。
选项 C: 深度优先搜索完全适用于有向图,通过递归或者借助栈来实现对有向图的深度优先遍历,按照一定的顺序访问有向图中的顶点,所以说深度优先搜索不适合有向图是错误的,该选项符合题意。
选项 D: 深度优先搜索本质上是一个递归的过程,例如从一个起始顶点出发,递归地访问它的邻接顶点,直到不能继续深入访问时再回溯,继续探索其他分支,所以该选项正确。
Fill the blank with correct C++ codes
In order to insert a new node s after the node which pointer q points to in a circular doubly linked list, we need to execute the following statements:
s->prior=q; |
答案:q->next->prior = s; q->next = s;
答案解释:
在循环双向链表中插入节点需要正确地调整各个节点之间的指针关系,以保证链表的结构完整性以及双向可遍历性和循环特性。
当要在指针 q 所指向的节点之后插入新节点 s
时,前面已经执行了两步操作:
s->prior=q;这一步将新节点s的前驱指针指向了当前节点q,使得从s往回找能找到q。s->next=q->next;这一步将新节点s的后继指针指向了原q节点的后继节点,也就是在逻辑上把s放到了q和原q的后继节点之间的位置。
接下来还需要进行两步关键操作来完善整个插入过程:
q->next->prior = s;这一步是很重要的,因为原q的后继节点(也就是q->next所指向的节点),它的前驱指针原本是指向q的,现在要在q后面插入s,所以需要将这个后继节点(q->next)的前驱指针更新为指向新插入的节点s,这样就保证了从原q的后继节点往回找能正确找到新插入的节点s。q->next = s;最后这一步是将q节点的后继指针更新为指向新插入的节点s,使得从q往后遍历链表时能正确地访问到新插入的节点s,从而完成了整个在循环双向链表中节点插入的操作,保证链表结构依然是循环且双向可正确遍历的状态。
所以完整的插入操作需要补充
q->next->prior = s; q->next = s; 这两条语句。
Prof that exchange sorts (Bubble sort, Selection sort, Insertion sort, etc. ) are \(\Theta(n^2)\) in average and worst case.
以下分别对冒泡排序(Bubble sort)、选择排序(Selection sort)、插入排序(Insertion sort)等常见交换排序在平均情况和最坏情况下时间复杂度为\(\Theta(n^2)\)(注意不是\(\Theta(n)\) 哦,这些排序算法的平均和最坏情况通常是\(\Theta(n^2)\))进行证明:
冒泡排序(Bubble sort)
- 最坏情况分析:
- 原理:在最坏情况下,待排序的数组是完全逆序的。比如数组\([n, n - 1, n - 2, \cdots, 1]\)。
- 对于长度为\(n\)的数组,第一轮比较需要进行\(n - 1\)次相邻元素的比较和交换操作,才能把最大的元素“浮”到最后位置;第二轮需要进行\(n - 2\)次比较交换操作,把第二大的元素放到倒数第二的位置,以此类推,总共需要进行的比较次数是\((n - 1)+(n - 2)+\cdots + 1\)。
- 根据等差数列求和公式\(\sum_{i = 1}^{n - 1}i=\frac{n(n - 1)}{2}\),其时间复杂度为\(O(n^2)\)。同时,容易看出其操作次数不可能低于\(n(n - 1)/2\)的某个常数倍(因为这些比较交换操作都是必须执行的),所以其最坏情况时间复杂度为\(\Theta(n^2)\)。
- 平均情况分析:
- 假设数组的所有可能排列是等概率出现的。对于任意两个元素,它们在最终排好序的位置上的先后顺序有两种可能(顺序正确或者顺序相反),且两种情况概率相等。
- 平均来说,大约一半的元素对是逆序的。而冒泡排序中交换操作的次数与逆序对的数量有关,逆序对的期望数量是\(n(n - 1)/4\)(基于概率论和组合数学相关知识推导),每次交换涉及到一定量的比较操作等开销,总的操作次数依然是\(\Theta(n^2)\)量级,所以平均情况时间复杂度也是\(\Theta(n^2)\)。
选择排序(Selection sort)
- 最坏情况分析:
- 原理:它的工作方式是每一轮从待排序元素中选择最小(或最大)的元素,然后放到已排序部分的末尾。不管输入数组是什么样的顺序,对于长度为\(n\)的数组,都需要进行\(n - 1\)轮选择操作。
- 在每一轮中,为了找到最小元素,都需要遍历剩余未排序的所有元素,第一轮要遍历\(n - 1\)个元素,第二轮遍历\(n - 2\)个元素,以此类推。总的比较次数同样是\((n - 1)+(n - 2)+\cdots + 1=\frac{n(n - 1)}{2}\),所以最坏情况时间复杂度为\(\Theta(n^2)\)。
- 平均情况分析:
- 由于选择排序的执行步骤不依赖于输入数组元素的初始顺序(它每一轮都是固定地找最小元素等操作),无论数组初始状态如何,比较次数都固定为\(\frac{n(n - 1)}{2}\)次左右,所以其平均情况时间复杂度也是\(\Theta(n^2)\)。
插入排序(Insertion sort)
- 最坏情况分析:
- 原理:在最坏情况下,比如对一个逆序的数组\([n, n - 1, n - 2, \cdots, 1]\)进行插入排序。对于第\(i\)个元素,需要将它与前面\(i - 1\)个已经排好序的元素依次比较并移动位置,才能插入到正确的地方。
- 当\(i = n\)时,总的比较和移动操作次数就是\(1 + 2 + \cdots + (n - 1)=\frac{n(n - 1)}{2}\),所以最坏情况时间复杂度为\(\Theta(n^2)\)。
- 平均情况分析:
- 平均情况下,对于一个随机排列的数组,平均来说每个元素大约需要与前面一半的已排序元素进行比较和移动操作。对于长度为\(n\)的数组,总的操作次数依然是\(\Theta(n^2)\)量级,其平均情况时间复杂度也是\(\Theta(n^2)\)。
综上所述,冒泡排序、选择排序、插入排序等常见的交换排序算法在平均情况和最坏情况下时间复杂度通常是\(\Theta(n^2)\),而不是\(\Theta(n)\)。
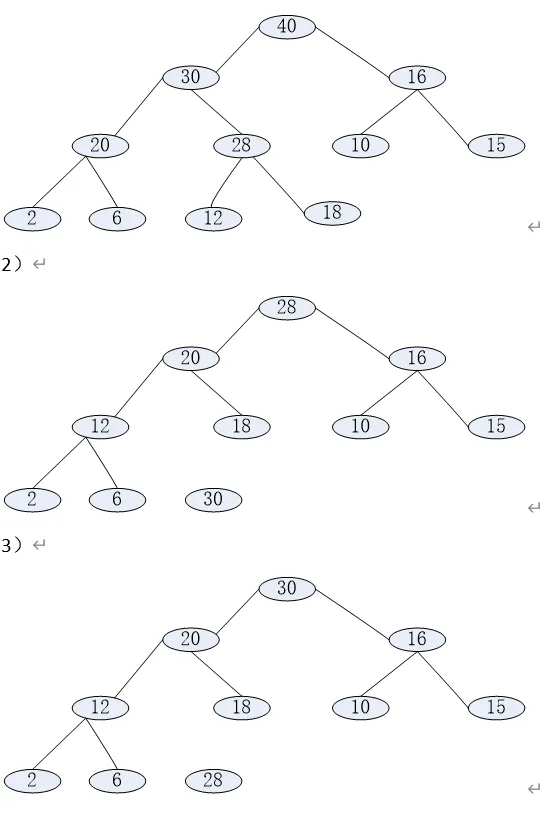
Please draw pictures to show the heaps that results from (6 scores)
adding 40 to the following heap;
deleting 30 from the following heap;
deleting 28 from the following heap.
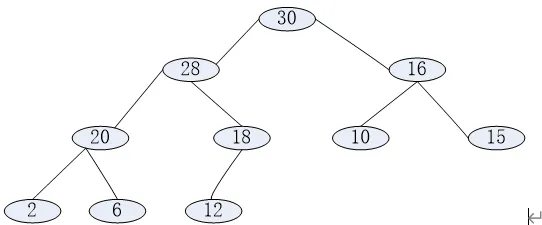
答案解释:
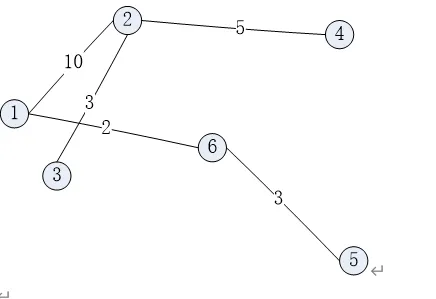
List the order in which the edges of the following graph are visited when running Prim's minimum-cost spanning tree algorithm starting at Vertex 1. Show the final MST.
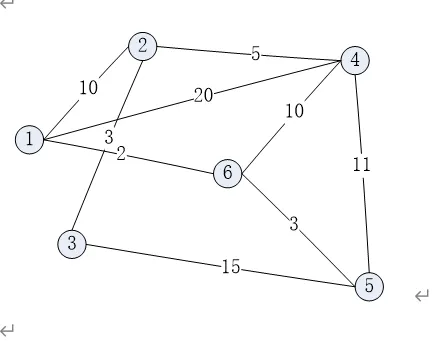
答案: